Analyzing Contextual Overlap in Multi-Class Mental Health Discourse Using Transformers and Explainable AI
This project investigates whether contextual transformer models can effectively differentiate between closely related mental health communities (Depression, Anxiety, BPD, SuicideWatch) and analyzes why contextual overlap leads to misclassification using explainable AI techniques.
Problem Statement
Mental health discourse on online platforms contains overlapping linguistic patterns across related conditions. While binary depression detection has been widely studied, multi-class differentiation between closely related communities such as Depression and SuicideWatch remains challenging. Misclassification between chronic depressive expression and acute suicidal ideation raises important concerns for automated risk detection systems.
Literature Review / Market Research
Prior research has primarily focused on binary classification of depression using lexical features and classical machine learning models. Recent studies employ transformer-based models for suicide risk detection; however, limited work explores multi-class contextual overlap and applies explainability methods to analyze confusion between related disorders.
Research Gap / Innovation
This work performs multi-class classification across five Reddit communities and integrates SHAP and LIME explainability techniques to investigate why contextual transformer models confuse Depression and SuicideWatch posts. The focus is not only performance improvement but interpretability of model behavior.
System Methodology
Dataset / Input
Reddit posts (2018-2019) from five communities: Depression, Anxiety, BPD, SuicideWatch, and merged Control subreddits. The final balanced dataset contains over 36,000 posts across five classes. Text was cleaned and tokenized with a maximum sequence length of 256 tokens.
Model / Architecture
Baseline models: TF-IDF with Logistic Regression and Linear SVM.
Advanced model: Fine-tuned BERT (bert-base-uncased) for multi-class classification.
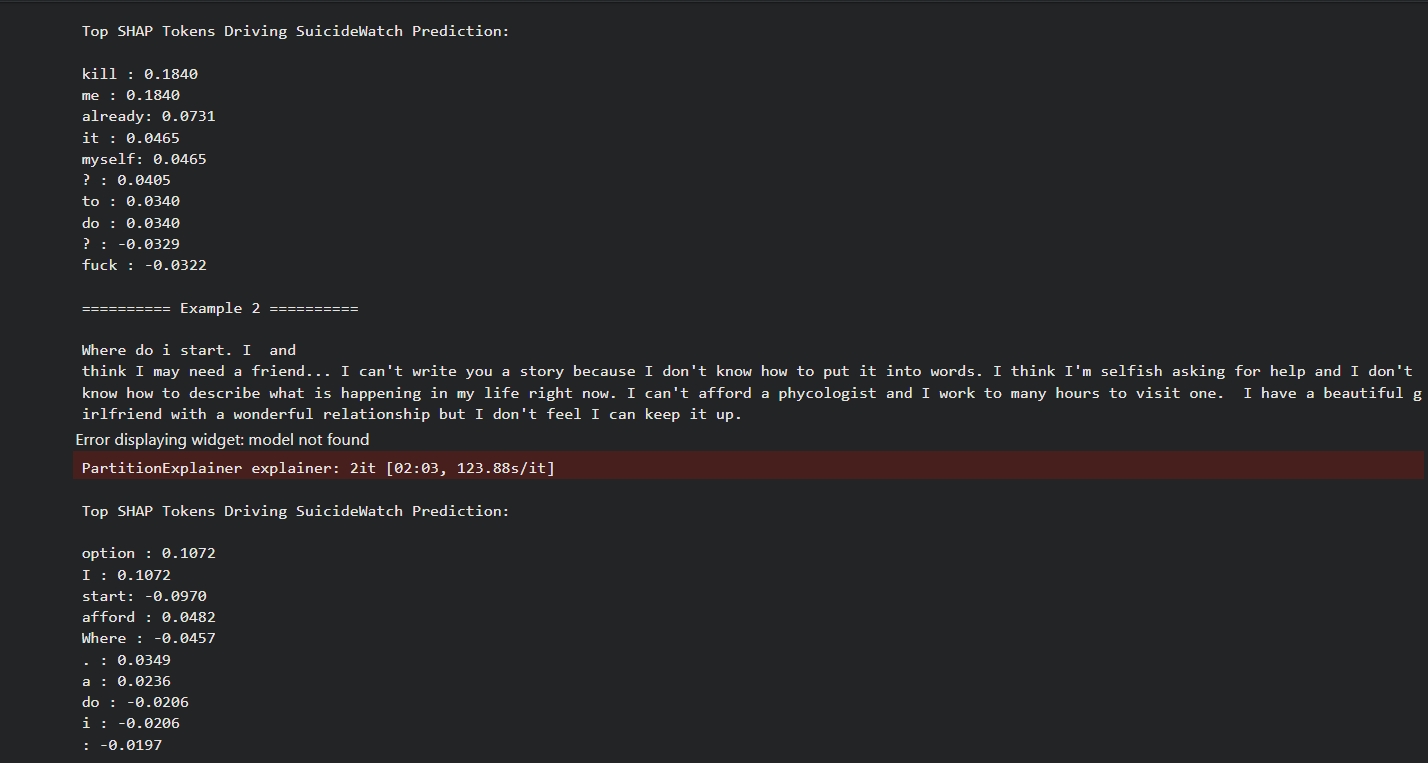
Explainability: LIME and SHAP were applied to analyze token-level contributions driving model predictions, particularly in Depression & SuicideWatch misclassifications.
Evaluation metrics: Accuracy, Macro F1-score, and Confusion Matrix analysis.
Live Execution
VIEW CODEResults & Analysis
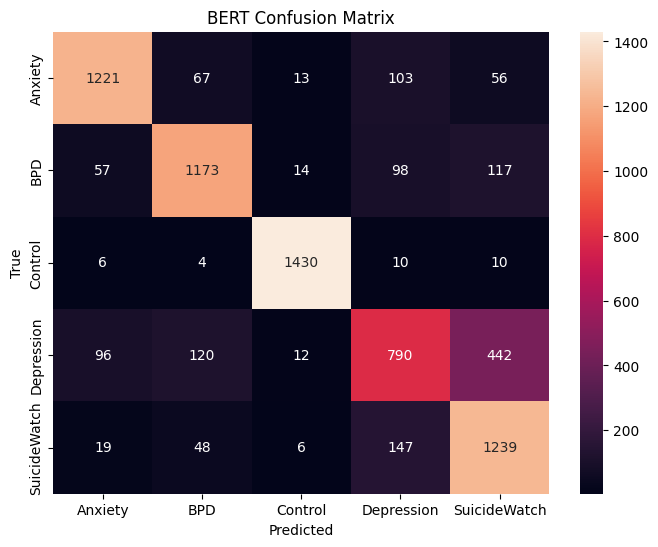
BERT improves macro F1-score compared to classical baselines; however, significant confusion persists between Depression and SuicideWatch. Explainability analysis reveals that contextual crisis-related phrases strongly influence SuicideWatch predictions, indicating lexical sensitivity to suicidal framing.
The confusion matrix reveals significant overlap between Depression and SuicideWatch classes, with 442 Depression posts misclassified as SuicideWatch. This supports the hypothesis that contextual crisis framing contributes to classification ambiguity.
BERT Confusion Matrix
Explainability Analysis (LIME & SHAP)
LIME Explanation Example

SHAP Explanation Example
Academic Credits
Project Guide
Dr Susheela Vishnoi
Team Member 1
Divyanshu Bhardwaj
23FE10CSE00063